開発
Sentiment Analysis through Natural Language Processing: A Classification Task with BERT
Cherubin Mugisha
Introduction
Today, with the wide use of the internet, handheld devices, and social media services, people are freer to express their feelings, share their thoughts, stories, emotions, and ideas on physical and non-physical things.
Companies, governments, and other organizations aiming to rely on surveys of public opinion found a fantastic opportunity to gather and analyze such freely shared information with a high quality of honesty. Problem Statement Customer Happiness has become the top priority for service & product-based companies. To an extent, some of the companies even appoint CHOs (Customer Happiness Officer) to ensure delivering a delightful customer experience.
Well, machine learning is now playing a pivotal role in delivering that experience. The ability to predict happy and unhappy customers give companies a nice head-start to improve their experience.
The groundbreaking introduction of Bidirectional Encoder Representations from Transformers (BERT) in 2018 by Google had written the new state-of-the-art in NLP. Transfer learning, particularly models like Allen AI’s ELMO, OpenAI’s Open-GPT, and Google’s BERT allowed researchers to smash multiple benchmarks with minimal task-specific fine-tuning and provided the rest of the NLP community with pre-trained models that could easily (with fewer data and less compute time) be fine-tuned and implemented to produce a state of the art results. Unfortunately, for many starting out in NLP and even for some experienced practitioners, the theory and practical application of these powerful models are still not well understood.
This post will explain how you can modify and fine-tune BERT to create a powerful NLP model that quickly gives you state-of-the-art results.
Advantages of Fine-Tuning
The Hugging face transformers in its version 4.6.0 provides general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 30 pre-trained architectures in 9000+ models with deep interoperability between TensorFlow and PyTorch and others.
In this tutorial, we will use BERT to train a text classifier. Specifically, we will take the pre-trained BERT model, add an untrained layer of neurons on the end, and train the new model for our classification task. Why do this rather than train a specific deep learning model (a CNN, BiLSTM, etc.) that is well suited for the specific NLP task you need? Well, leveraging a pretraining process weights to accomplish a certain task of yours, using your data, transfer learning, and a little bit more training. This process has some advantages such as:
- Faster Development
- Less training Data
- Less training time
- Better Results
Data
Machine learning is now playing a pivotal role in delivering services beyond traditional statistics. The ability to predict happy and unhappy customers give companies a nice head-start to improve their experience.
TripAdvisor is the world’s largest travel site where you can compare and book hotels, flights, restaurants etc. The data set provided in this challenge consists of a sample of hotel reviews provided by the customers. Analyzing customers’ reviews could help them understand about the hotels listed on their website i.e. if they are treating customers well or if they are providing hospitality services as expected.
In this challenge, we will predict if a customer is happy or not happy. For more details about the dataset, refer to this link.
Here is an example of how to import and visualize the data in your python notebook
!pip install transformers
import os
import pandas as pd
print('Downloading dataset...')
# The URL for the dataset zip file.
url = 'https://he-s3.s3.amazonaws.com/media/hackathon/predict-the-happiness/predict-the-happiness/f2c2f440-8-dataset_he.zip'
# Download the file (if we haven't already)
if not os.path.exists('./predict_happiness.zip'):
wget.download(url, './predict_happiness.zip')
# Load the dataset into a pandas dataframe.
df = pd.read_csv("./train.csv", header=0, names=['ID','description', 'browser', 'device', 'label'])
# Report the number of sentences.
print('Number of training sentences: {:,}\n'.format(df.shape[0]))
# Display 10 random rows from the data.
df.sample(10)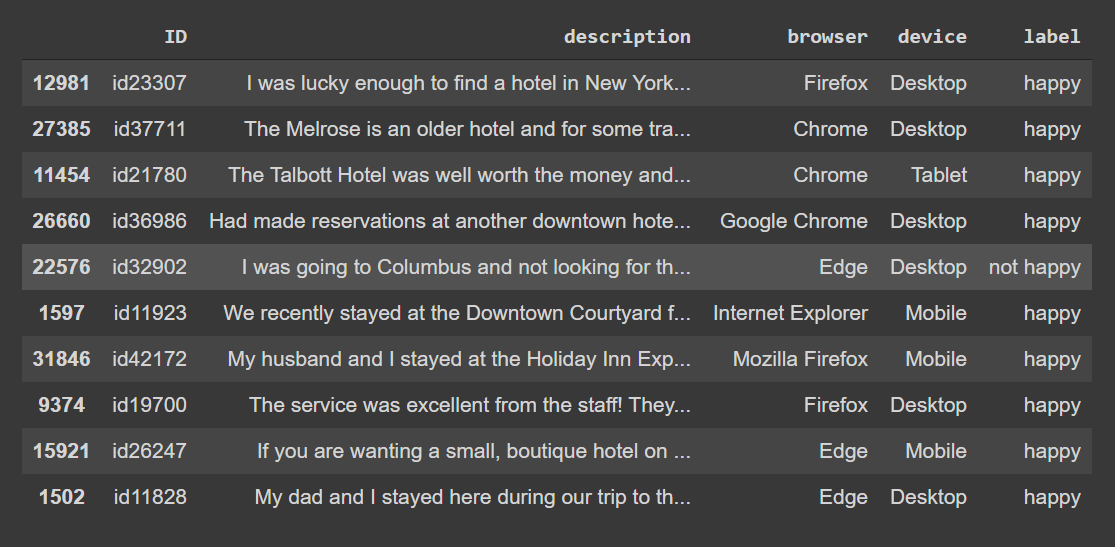
Customers reviews and label data
Sentence Classification task
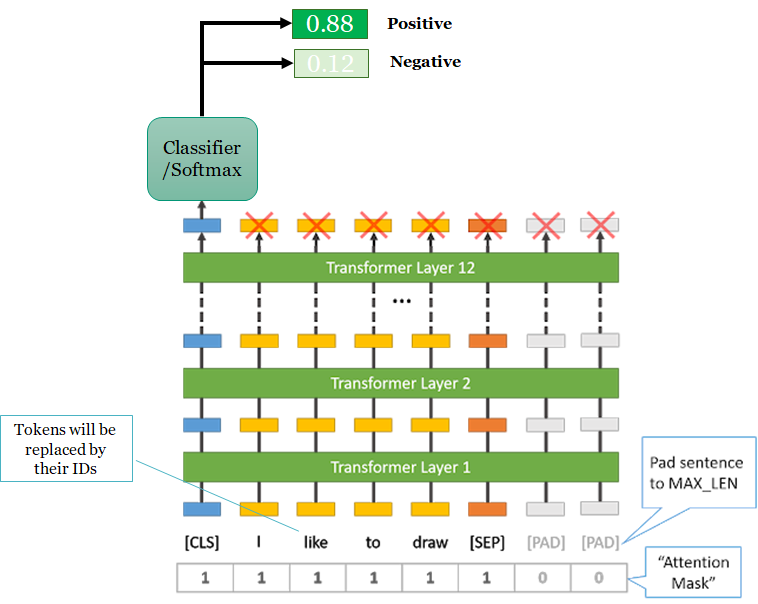
BERT has a class for sentence classification tasks called BertForSequenceClassification. This is the normal BERT model with an added single linear layer on top for classification that we will use as a sentence classifier. As we feed input data, the entire pre-trained BERT model and the additional untrained classification layer is trained on our specific task.
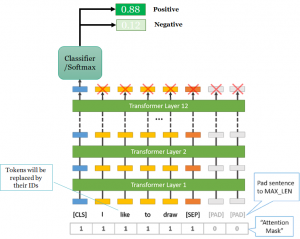 The sentence classification fine-tuning task consists of leveraging the weights from a pre-trained model, and use your data to train the classifier layer, using by default the [CLS] token embeddings or any layer by aggregating the embeddings to make sentence embeddings.
The sentence classification fine-tuning task consists of leveraging the weights from a pre-trained model, and use your data to train the classifier layer, using by default the [CLS] token embeddings or any layer by aggregating the embeddings to make sentence embeddings.
There are a few different pre-trained BERT models available. “bert-base-uncased” means the version that has only lowercase letters (“uncased”) and is the smaller version of the two (“base” vs “large”).Here is the full list of the currently provided pre-trained models together with a short presentation of each model. At the time of this blog bert-base-multilingual-cased is the recommended one. Trained on cased text in the top 104 languages with the largest Wikipedia.
Tokenization and input formatting
As for any ML model, BERT has its own requirement for an input format. We need to transform our text data into numbers that BERT can be trained on using word-piece tokenization. This process can be done by importing BertTokenizer class from transformers. When we convert all of our sentences, we can use the tokenize.encode function to create tokens and their IDs, rather than calling tokenize and convert_tokens_to_ids separately.
However, the Huggingface library provides a more advanced function called tokenizer.encode_plus that combines multiple steps by adding attention masks on the inputs tensor. This step will:
- Split the sentence into tokens.
- Add the special
[CLS]and[SEP]tokens. - Map the tokens to their
IDs. - Pad and truncate all sentences to the same length.
- Create the attention masks which explicitly differentiate real tokens from
[PAD]tokens.
# Tokenize all of the sentences and map the tokens to their word IDs.
input_ids = []
attention_masks = []
# For every sentence...
for sent in description:
encoded_dict = tokenizer.encode_plus(
sent, # Sentence to encode.
add_special_tokens = True, # Add '[CLS]' and '[SEP]'
max_length = 64, # Pad & truncate all sentences.
pad_to_max_length = True,
return_attention_mask = True, # Construct attn. masks.
return_tensors = 'pt', # Return pytorch tensors.
)
# Add the encoded sentence to the list same for the attention masks.
input_ids.append(encoded_dict['input_ids'])
attention_masks.append(encoded_dict['attention_mask'])
# Convert the lists into tensors.
input_ids = torch.cat(input_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
labels = torch.tensor(labels)
Training and Test Loops
Once we have tensors of inputs, we can choose to split the dataset into training and validation sets, especially to avoid overfitting for the final model. For our case, we divided the dataset into a ratio of 0.85 by 0.15.
Once we have our model loaded, we need to grab the training hyperparameters within the stored model. For the purposes of fine-tuning, the authors recommend choosing from the following values (from Appendix A.3 of the BERT paper):
- Batch size: 16, 32 (->32)
- Learning rate (Adam): 5e-5, 3e-5, 2e-5 (->2e-5)
- Number of epochs: 2, 3, 4 (->6 to check the why)
- Epsilon parameter: 1e-8 is the default
You can find the creation of the AdamW optimizer in run_glue.py here. It’s recommended to use a scheduler to control the learning weight decay by taking larger steps at the beginning and smaller ones once the model has learned something to avoid missing the optimum value.
Note that BERT does not require many training epochs. Most of the time, 2 to 4 epochs are enough. To take advantage of parallelism, it’s recommended to use an accelerator such as GPU or TPU if you have one. In my case, I used the GeForce RTX 3090 with 24GB of memory. We have the model loaded on the device, data tensors prepared, and hyperparameters set, we can start the training loop. Below is an overview of the training loop once we start feeding our data into the model.
#This code was adapted to this task but all the credits go to https://colab.research.google.com/drive/1pTuQhug6Dhl9XalKB0zUGf4FIdYFlpcX
import random
import numpy as np
seed_val = 27
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
training_stats = []
# For each epoch...
for epoch_i in range(0, epochs):
# ========================================
# Training
# ========================================
# Reset the total loss for this epoch.
total_train_loss = 0
# Put the model into training mode.
model.train()
# For each batch of training data...
for step, batch in enumerate(train_dataloader):
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
model.zero_grad()
# Perform a forward pass (evaluate the model on this training batch).
loss, logits = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
# Accumulate the training loss over all of the batches so that we can
# calculate the average loss at the end. `loss` is a Tensor containing a
total_train_loss += loss.item()
# Perform a backward pass to calculate the gradients.
loss.backward()
# Clip the norm of the gradients to 1.0. is a technic preventing the exploding gradients
# This is to help prevent the "exploding gradients" problem.
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# Update parameters and take a step using the computed gradient.
optimizer.step()
# Update the learning rate.
scheduler.step()
# Calculate the average loss over all of the batches.
avg_train_loss = total_train_loss / len(train_dataloader)
# Measure how long this epoch took.
training_time = format_time(time.time() - t0)
# ========================================
# Validation
# ========================================
# After the completion of each training epoch, measure our performance on
# our validation set.
# Put the model in evaluation mode--the dropout layers behave differently
# during evaluation.
model.eval()
# Tracking variables
total_eval_accuracy = 0
total_eval_loss = 0
nb_eval_steps = 0
# Evaluate data for one epoch
for batch in validation_dataloader:
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
# Tell pytorch not to bother with constructing the compute graph during
with torch.no_grad():
# Forward pass, calculate logit predictions.
(loss, logits) = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
# Accumulate the validation loss.
total_eval_loss += loss.item()
# Move logits and labels to CPU
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
# Calculate the accuracy for this batch of test sentences, and
# accumulate it over all batches.
total_eval_accuracy += flat_accuracy(logits, label_ids)
# Report the final accuracy for this validation run.
avg_val_accuracy = total_eval_accuracy / len(validation_dataloader)
print(" Accuracy: {0:.2f}".format(avg_val_accuracy))
# Calculate the average loss over all of the batches.
avg_val_loss = total_eval_loss / len(validation_dataloader)
# Record all statistics from this epoch.
training_stats.append(
{
'epoch': epoch_i + 1,
'Training Loss': avg_train_loss,
'Valid. Loss': avg_val_loss,
'Valid. Accur.': avg_val_accuracy,
}
)
print("")
print("Training complete!")
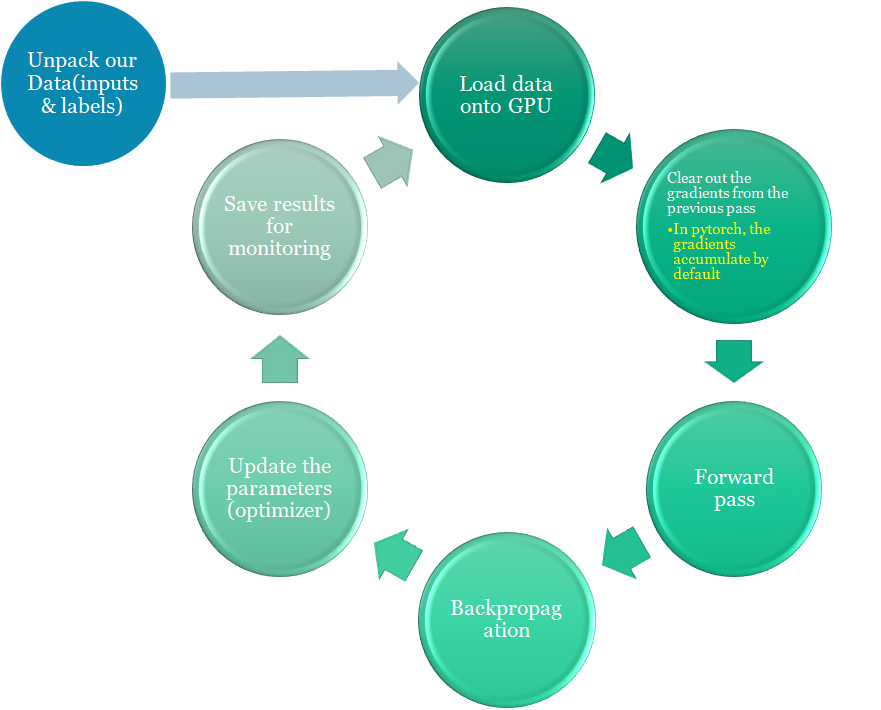
BERT for sequence classification training loop
There’s a lot going on, but fundamentally for each pass in this loop, we have a training phase and a validation phase. PyTorch also has some beginner tutorials which you may also find helpful.
Note that this loop is almost similar to the test one except that you have to implicitly tell the model that it’s training or testing so that the dropout and batchnorm layers will accordingly behave differently
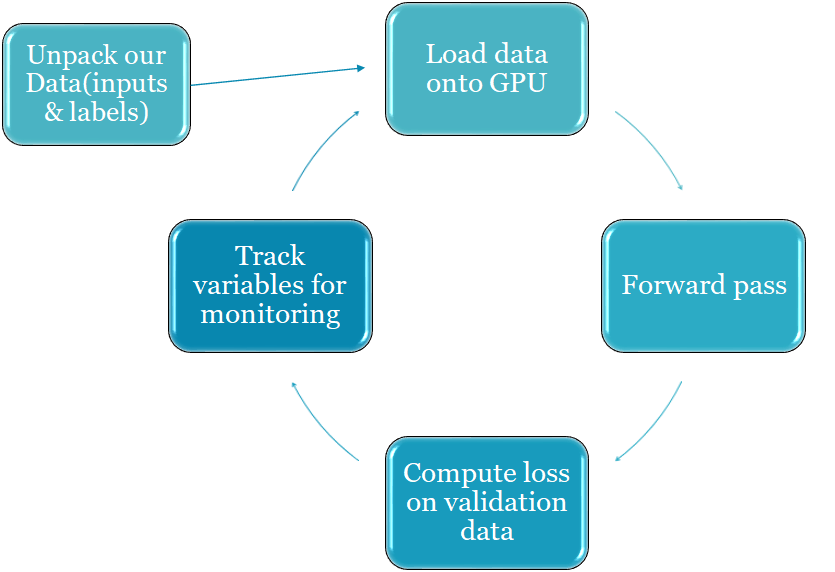
Bert for sequence Classification test Loop
This post demonstrates that with a pre-trained BERT model you can quickly and effectively create a high-quality model with minimal effort and training time using the PyTorch interface, regardless of the specific NLP task you are interested in.
- Tweet
-

 2026/03/06
2026/03/06 2025/12/12
2025/12/12 2024/12/06
2024/12/06 2024/09/13
2024/09/13 2024/05/17
2024/05/17 2024/05/10
2024/05/10 2024/01/05
2024/01/05 2023/08/18
2023/08/18
{kind=link}