Eyes, JAPAN
Reinforcement Learning 101 — Embracing Manager-Based (Hierarchical) Strategies
Charu
Reinforcement Learning 101: Understanding Manager-Based (Hierarchical) Control

Introduction
Reinforcement Learning (RL) teaches agents to learn from trial-and-error interactions—receiving rewards for good actions and penalties for poor ones.
It’s powerful for tackling tasks involving sequential decision-making where the goal is to maximize cumulative rewards.
Today, we’ll break down RL basics and explore Manager-Based (Hierarchical) Reinforcement Learning, where high-level and low-level policies come together—adding structure to complex learning tasks.
What Is Reinforcement Learning?
RL enables an autonomous agent to make decisions by interacting with an environment, aiming to maximize long-term reward.
Unlike supervised learning, RL doesn’t use labeled datasets—it learns from direct feedback.
Typical RL Approaches
-
Model-Free Methods (e.g., Deep Q-Networks): Learn policies directly from experience.
-
Model-Based Methods: Build models to simulate and plan from the environment.
Why it matters: RL powers robotics, game AI, and resource management by allowing systems to learn decisions interactively without explicit supervision.
The Markov Decision Process (MDP)
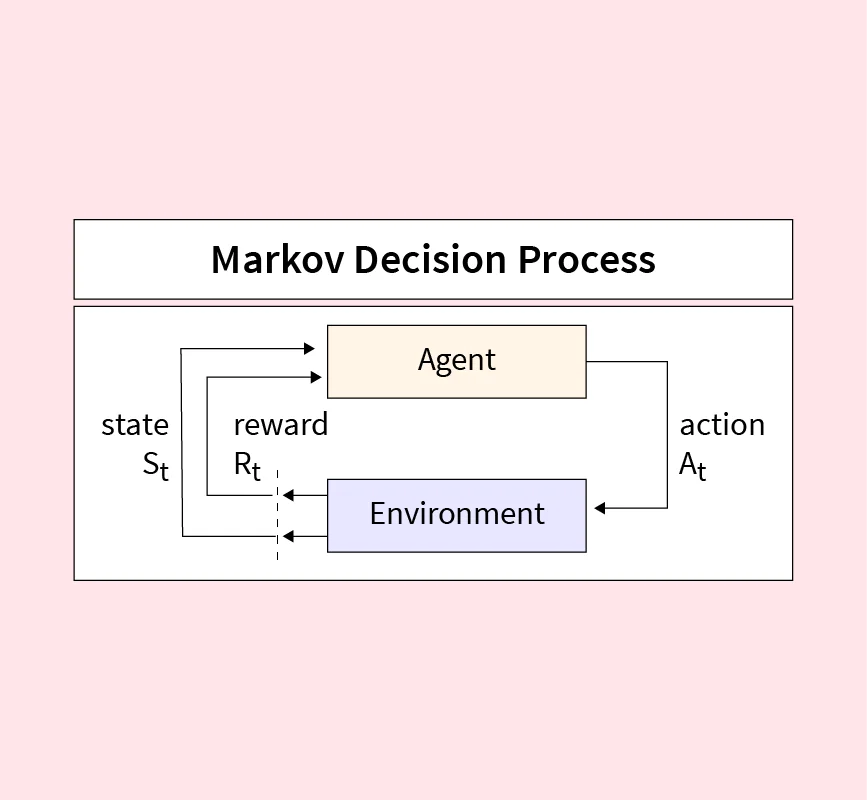
RL problems are usually formalized as a Markov Decision Process (MDP).
An MDP is defined by the 5-tuple (S, A, P, R, γ):
-
S (States): All possible situations.
-
A (Actions): Choices the agent can take.
-
P (Transition Probability): Likelihood of moving to a new state given an action.
-
R (Reward): Feedback received after taking an action.
-
γ (Gamma): Discount factor that controls how much future rewards matter compared to immediate ones.
Goal: Learn an optimal policy (π*) that maximizes expected long-term reward.
Key RL Concepts
-
Policy (π): Strategy mapping states → actions.
-
Value Functions (V(s), Q(s,a)): Predict expected future rewards for states or actions.
-
Return (G): Total discounted reward:
-
Exploration vs. Exploitation
-
Exploitation – “Play it safe”
The agent chooses the best-known action that has given high rewards so far.
This maximizes short-term performance because it uses existing knowledge.
However, if the agent only exploits, it can get stuck in a local optimum and miss out on better long-term strategies. -
Exploration – “Take a risk to learn”
The agent tries a new action, even if it doesn’t look optimal right now.
This helps discover hidden rewards or better strategies in the long run.
Exploration is essential in early learning, but it may temporarily reduce rewards since not all new actions are beneficial.
-
-
Discount Factor (γ): Low γ = short-term focus; high γ = long-term planning.
What Is an Epsilon-Greedy Policy?
Balancing exploration vs. exploitation is crucial.
The ε-greedy policy does this by:
-
With probability (1 – ε): Choose the best-known action.
-
With probability ε: Choose a random action.
Example: With ε = 0.1, the agent explores 10% of the time and exploits 90% of the time.
Often ε is reduced over time (“annealed”) so the agent explores less as it learns.
What Is Hierarchical Reinforcement Learning (HRL)?
Hierarchical RL (HRL) adds structure by breaking down complex tasks into smaller sub-tasks, enabling multiple levels of policy abstraction rather than flat action–state mappings.
Benefits of HRL
-
Efficiency in Complex Environments
Sub-tasks focus on smaller state spaces, improving learning speed. -
Handling Sparse Rewards
Intermediate goals make it easier to learn when rewards are rare. -
Reusability & Transfer Learning
Learned skills (sub-policies) can be reused across different tasks.
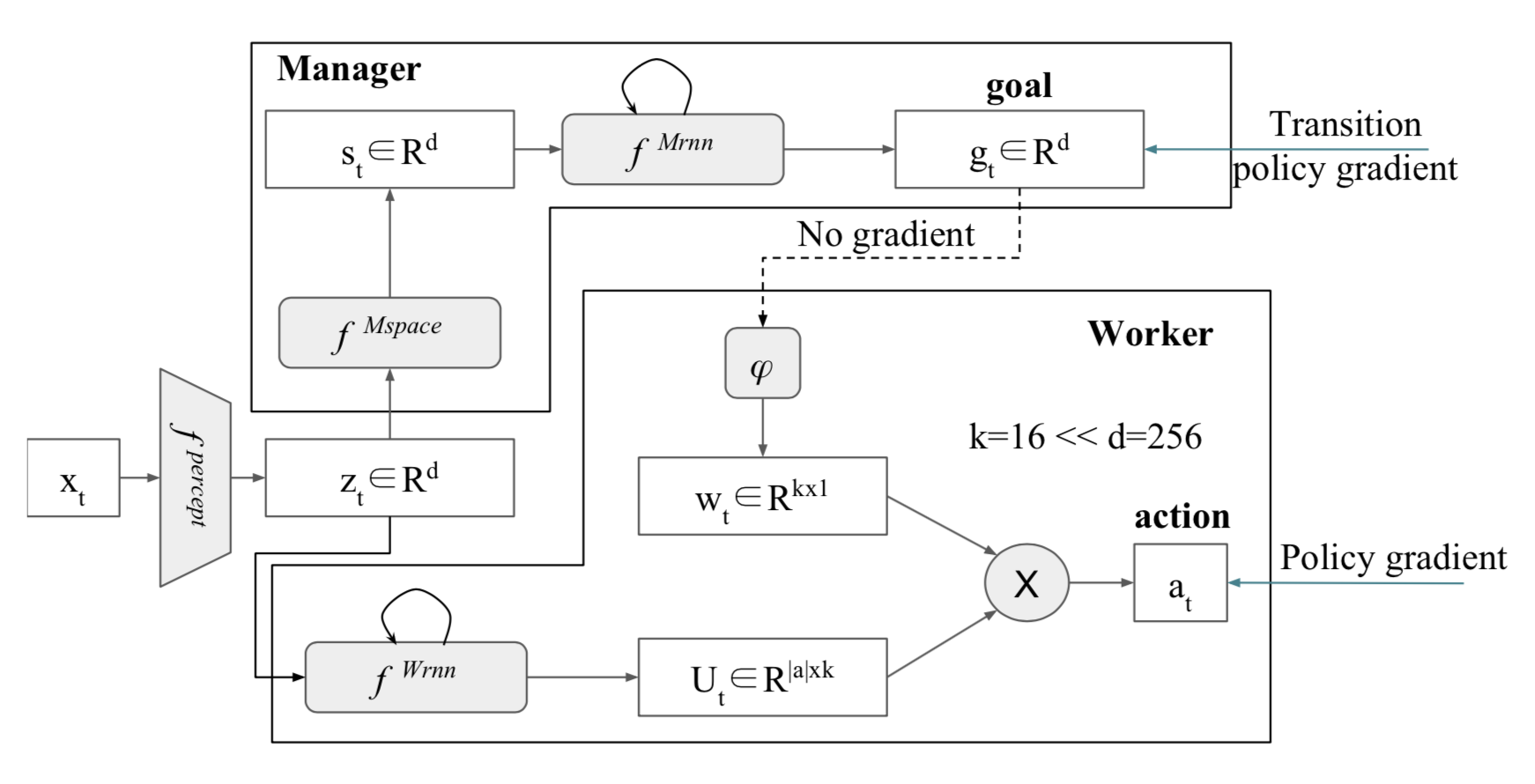
Manager-Based / Feudal Reinforcement Learning
In Manager-Based RL (like Feudal RL / FeUdal Networks (FuN)):
-
The Manager issues higher-level goals.
-
The Worker executes low-level actions to fulfill those goals.
-
This creates a natural separation of concerns and improves long-term planning.
Example: FeUdal Networks (FuN)
-
Manager: Sets latent goal vectors.
-
Worker: Uses these goals to select primitive actions.
-
Result: Better performance in tasks with long-term dependencies (e.g., DeepMind Lab, Atari).
Other HRL Frameworks
-
Options Framework: Defines macro-actions with initiation, policy, and termination conditions.
-
MAXQ Hierarchy: Splits value functions into immediate vs. hierarchical rewards.
-
Recent Advances:
-
End-to-end learning of subgoals dynamically.
-
Hybrid setups: model-based managers + model-free workers.
-
Real-World HRL Applications
| Domain | Example Use Case |
|---|---|
| Navigation & Robotics | Subgoals like “reach room A” improve exploration and efficiency. |
| Logistics/Warehousing | Manager assigns picking tasks; workers execute them, boosting throughput. |
| Industrial Control (HVAC) | HRL optimizes energy usage while respecting time-scale constraints. |
| Video Summarization | Manager-worker models handle sparse rewards, outperforming supervised methods. |
Summary Table
| Concept | Description |
|---|---|
| Reinforcement Learning | Learning via interaction to maximize long-term reward |
| MDP (S, A, P, R, γ) | Framework for modeling RL under uncertainty |
| Policy (π) | Strategy mapping states → actions |
| Value Functions | Estimate expected cumulative reward |
| Epsilon-Greedy | Mixes exploration (random actions) and exploitation (best action) |
| Hierarchical RL (HRL) | Decomposes tasks into sub-policies at different abstraction levels |
| Manager-Based RL | Manager sets subgoals; Worker executes them |
| Frameworks | FeUdal Networks, Options, MAXQ, hybrid methods |
| Applications | Robotics, logistics, HVAC, summarization |
Conclusion (Massive Ending)
Reinforcement Learning equips agents with autonomy—but coupling it with Manager-Based Hierarchy unlocks deeper structure, strategy, and scalability.
This duality brings us closer to human-like reasoning, capable of tackling long-horizon tasks across diverse domains with clarity and control.
- Tweet
-

 2026/01/23
2026/01/23 2025/12/12
2025/12/12 2025/12/07
2025/12/07 2025/11/06
2025/11/06 2025/10/31
2025/10/31 2025/10/24
2025/10/24 2025/10/03
2025/10/03 2025/08/30
2025/08/30