Eyes, JAPAN
A deeper dive into git hooks
Justin
Most of us programmers are lazy.
We don’t like doing tedious tasks such as running a formatter to clean code up, or running a linter to check whether there are issues with your code, or running tests every time you make a change to make sure nothing blows up, so we generally relegate these to the continuous integration (CI) pipeline, e.g. the service that provides that little “build successful” image/badge on the READMEs of some repositories.
However, it is wasteful of CI minutes to run some of these tasks; you know how expensive CI minutes can get nowadays, and you need those minutes to run actual tests.
Well, thankfully, you can have both automation and local execution because of a relatively unknown tool called git hooks.
Or can we?
You may be wondering what a git hook is; I’d recommend you read a previous blog post explaining the basics here.
I won’t be reiterating on what was already said; I’ll be explaining more on what they are and the problems of using them in the modern workflow in this post.
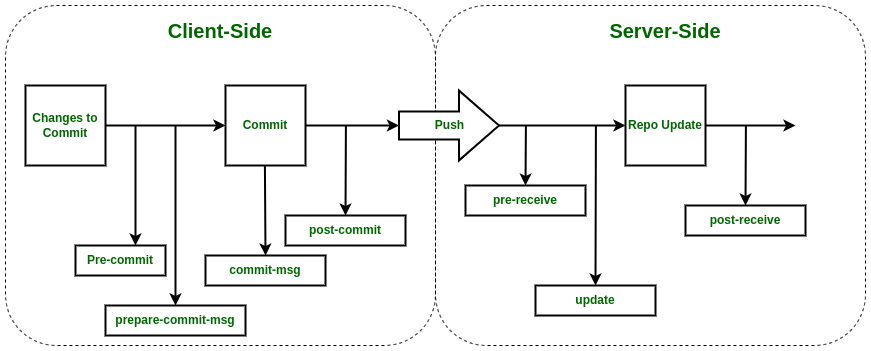
The bigger picture
What really is a git hook?
Well, we were just told that it is a script, but in reality it can be any binary or executable; the first line in their script says to run this file with Bash.
(Pretty nice, I’d say. I wouldn’t wish upon my worst enemies to write a Bash script).
You can use any language or runtime you want, just be careful that all of the machines that you use have the means to use that runtime.
Nowadays, safe bets would be Perl or Python, since most operating systems come with them installed by default.
What exactly can it do?
What a hook can do depends on what kind of hook it is.
There are two kinds of hooks basing on how they are run; client-side and server-side hooks.
“Client-side” here means that the hook will run when you run git on your local machine.
“Server-side” here means that the hook will run when the repository host receives your changes when you push your repository.
All of this information is just a condensed form of the documentation here
For the client-side hooks, they have this layout:
- pre-commit:
- runs: before commit starts
- inputs: none
- outputs: status 0 to continue commit, anything else to abort
- typical use cases:
- linting your repository
- running tests
- checking for formatting errors and missing documentation
- preventing a commit from being made when there is a “secret” (data that should be secret, like a password or a service token) in the commit
- notes: changes to the repository during the hook is not staged in the commit, so please return a non-zero status
- prepare-commit-msg:
- runs: before you’re able to input a commit message
- inputs:
- the path a the file that holds the commit message so far
- where the commit message was taken from, which can be:
- message (if a -m or -F option was given)
- template (if a -t option was given or the configuration option commit.template is set)
- merge (if the commit is a merge or a .git/MERGE_MSG file exists)
- squash (if a .git/SQUASH_MSG file exists)
- commit, followed by a commit object name (if a -c, -C or –amend option was given)
- the commit hash if this is an amended commit
- outputs: status 0 to continue commit, anything else to abort
- typical use cases:
- automatically filling out a commit message template if there is enough information (for example, when a merge commit is made)
- commit-msg:
- runs: after you input a commit message
- inputs:
- the path a the file that holds the commit message
- outputs: status 0 to continue commit, anything else to abort
- typical use cases:
- ensuring the commit message is structured as desired
- validating that the commit message contents accurately describes the staged changes
- post-commit:
- runs: after the commit has been made
- inputs: none
- outputs: none (e.g. it cannot abort the commit, as it has already been made)
- typical use cases:
- sending an email to a core developer if they’re mentioned in the commit message
- messaging a CI system to build and test the committed code
- automatically closing issues when a commit says “Fixes issue#nnn” or similar
- in general, notifying
For server-side hooks, they have this layout:
- pre-receive:
- runs: when you push to a remote repository, before the server updates its repository
- inputs:
- a list of changed references (refs) (the part of a commit that looks like this is called a ref: “d4e7f5d”)
- every line is a changed reference; the line format looks like “<old ref> <new ref> <reference name>”
- reference name is either the head of a branch, or a tag (which are used for versioning)
- some environment variables, which I will not explain here; you may find the explanation in the git hook documentation
- a list of changed references (refs) (the part of a commit that looks like this is called a ref: “d4e7f5d”)
- outputs:
- status 0 to continue the receive operation (the update hook may still abort), anything else to abort
- standard output and error is sent back to the client
- typical use cases:
- all use cases of pre-commit hooks but run on the server to prevent committers from skipping them
- preventing merges of changes by the same committer
- update:
- runs: before every changed reference is applied
- inputs: three CLI arguments new ref, old ref, reference name (similar to what pre-receive gets)
- outputs: status 0 to update the ref, anything else to reject the update
- typical use cases:
- rejecting individual reference updates
- ensuring that your history is not rewritten by tools like `git rebase` or cherry-picking
- disallowing changing tags
- having an allowlist of people who can push to certain branches
- post-receive:
- runs: after the server has updated the repository
- inputs: the same as pre-receive
- outputs: the same as pre-receive
- typical use cases:
- all use cases of post-commit hooks but run on the server to prevent committers from skipping them
- notes: no changes can be done to the data in the repository in this hook
Hidden problems
One issue you might encounter is that, unfortunately, client-side git hooks are not copied whenever you clone your repository from remote.
That means whenever you move to a new machine, or when you change your hooks, you would need to copy your client-side git hooks.
That gets annoying quick, but luckily there are some solutions.
The easy (and somewhat hacky) solution is to move your git hooks elsewhere to be able to commit them within the repository, then to configure git to look at that folder for the hooks.
The downside of this is that you will have extra configuration to add to every repository you want to have synchronised hooks for, which may also be annoying.
$ git config core.hooksPath .githooks $ mkdir .githooks $ touch .githooks/pre-commit ...
Another solution is to use server-side git hooks instead.
You’ll quickly discover another issue, though: Public git repository hosts generally block server-side git hooks, since you’re essentially running arbitrary code on their servers.
(Of course, you could sandbox that with virtual machines or containers similar to how cloud CI works, so I’m not sure why it is still blocked. Perhaps it would be complicated to run a git server that had to be aware of containers and whatnot).
If you really do not want to have an extra directory in your repository, then you can use whatever solution your repository host has made to replace server-side hooks.
On GitHub, that would be GitHub actions; I’m not sure of what other hosts provide.
How to use these is out of scope for this post, but perhaps I will talk about how to set them up in the next post.
So?
Git hooks are very useful when all of the users of your remote repository can be trusted and you don’t want to set up more infrastructure for automating tasks.
Nowadays, when every company is not self hosting its own repository hosts, git hooks have limited use.
It is good to learn more about these tools even if they are now sparingly used, because there may come a time where git hooks fit perfectly into the problem you’re facing.
I hope this article helps you when that time comes.
- Tweet
-

 2026/02/27
2026/02/27 2026/01/23
2026/01/23 2025/12/12
2025/12/12 2025/12/07
2025/12/07 2025/11/06
2025/11/06 2025/10/31
2025/10/31 2025/10/24
2025/10/24 2025/10/03
2025/10/03