エンジニア向け
日本語を身に付けたAmazon Transcribeの実力を試す
shimizu

(この記事は、Qiitaに投稿した記事を転載したものです)
Amazon Transcribeが日本語に対応した
Amazon Web Service (AWS)では、機械学習を応用したサービスとして「Amazon Transcribe」という自動音声認識の機能が提供されています。このサービスを使うと会議や電話、あるいは映像コンテンツに含まれる会話など、録音済みの音声データをテキストに変換する「文字起こし」を行うことが出来ます。人間が音を耳で聞いてキーボードから入力するには手間と時間がかかりますが、そこをうまく自動化することで作業コストを抑えられます。
そのAmazon Transcribeが、日本語音声にも対応したと先月発表されました。
Amazon Transcribe が、音声のテキスト変換に 7 つの言語を追加
利用料金
Amazon Transcribeの利用料金は、こちらに掲載されているとおり「1秒あたり 0.0004ドル」となります。
「1時間あたり 1.44ドル(=約160円)」という価格ですので、気軽に試せるのではないでしょうか。さらに、無料利用枠が設定されており、初回利用時から1年間は「1か月あたり1時間まで無料」となりますので、トライしてみない手はありません。
なお、医療に関する音声に特化した「Amazon Transcribe Medical」というサービスも別途用意されています。こちらは医師と患者の会話や遠隔医療での音声記録など、複雑な医療言語の文字越しを可能にするようチューニングされており、臨床現場システムとの統合を想定した作りになっています。利用料金は「1秒あたり 0.00125ドル」と、一般向けのTranscribeの約3倍になっていますが、「1年間月1時間」の無料利用枠は適用されます。
自動認識を試す
それでは、実際にAmazon Transcribeで音声の文字起こしを試してみましょう。変換対象の音声ファイルとして、こちらで公開されている朗読音声(ファイル名: rd162.mp3)を利用しました。
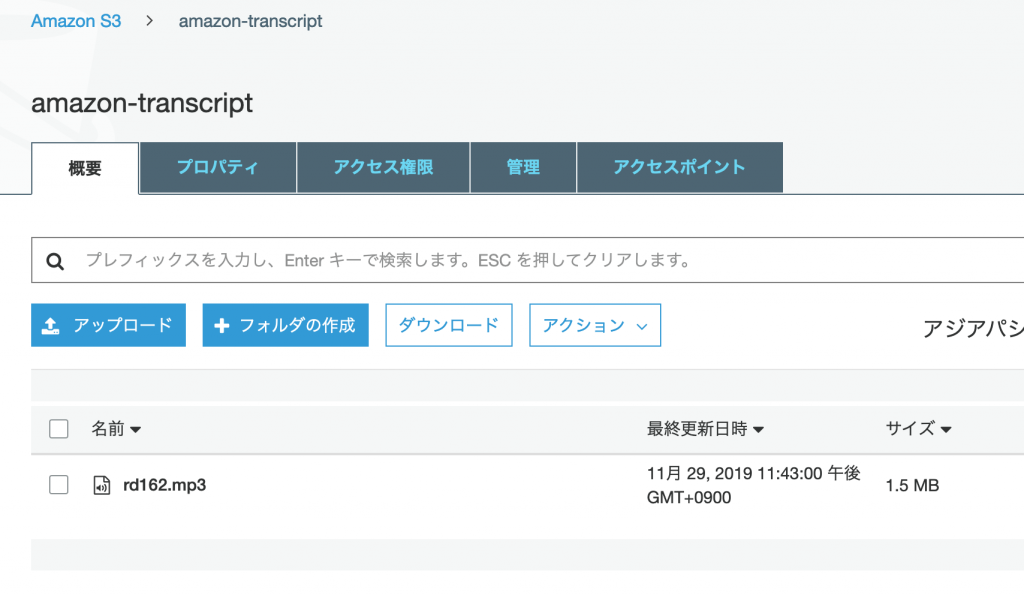
Transcribeでは、変換元のファイルをS3上に保存することになりますので、まずはファイルをアップロードします。ここでは、「s3://amazon-transcript/rd162.mp3」というパスにアップロードしました。
ファイルの準備ができましたので、続いて変換処理を行ってみましょう。
AWSコンソールのサービス一覧から「Amazon Transcribe」を開きます。
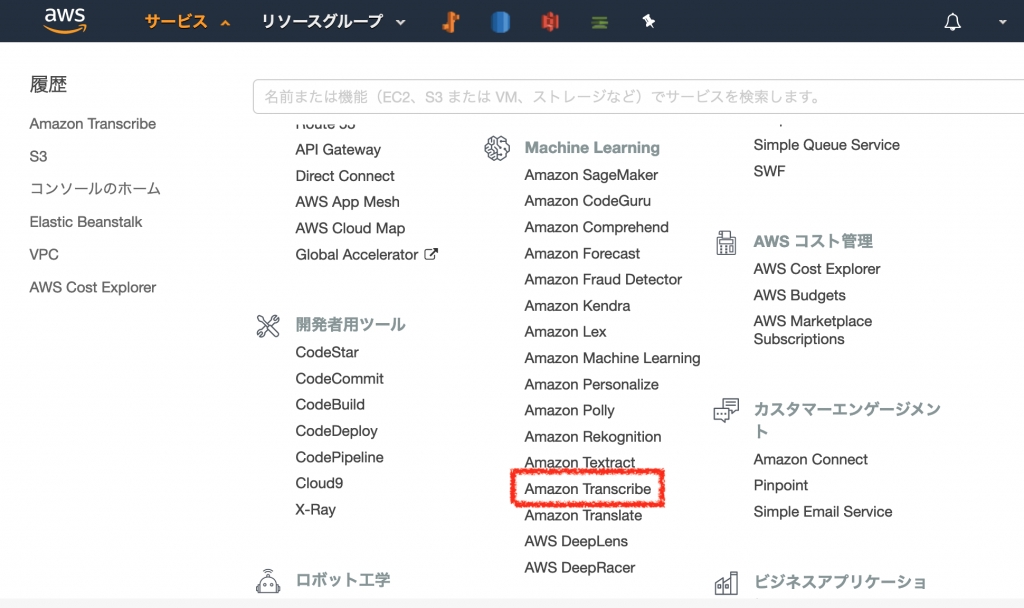
画面右側にある「Create transcription job」を押して、変換ジョブを作成する画面を開きます。
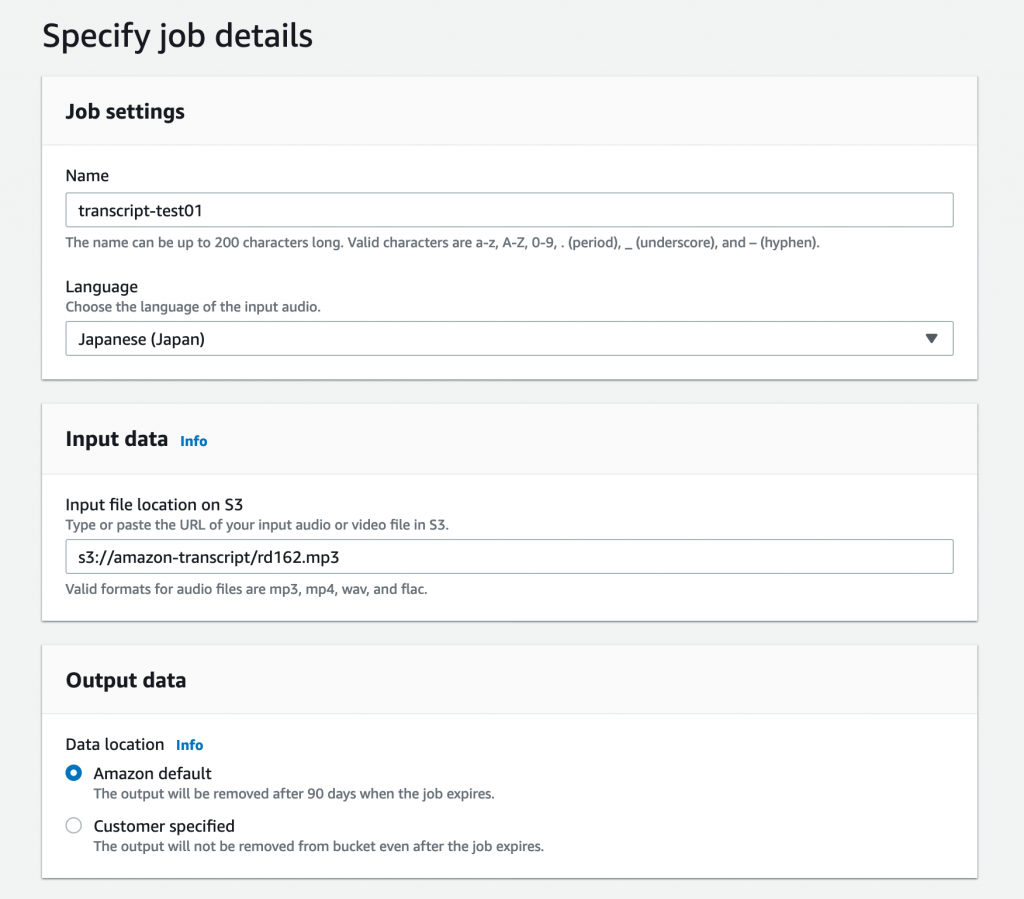
ジョブの設定では、以下のように記入してから「Next」ボタンを押します。
- Job settings
- Name: transcribe-test01 (このジョブの名前を英数字で記入する)
- Language: 「Japanese (japan)」を選択
- Input data
- Input file location on S3: s3://amazon-transcript/rd162.mp3(s3://[バケット名]/[ファイル名])
- Output data
- Data location: 「Amazon default」にチェックを入れる
次のオプション画面では、デフォルト設定のまま「Create」を押します。
変換ジョブ項目が作成され、「In progress」(処理中)のステータス表示になりました。
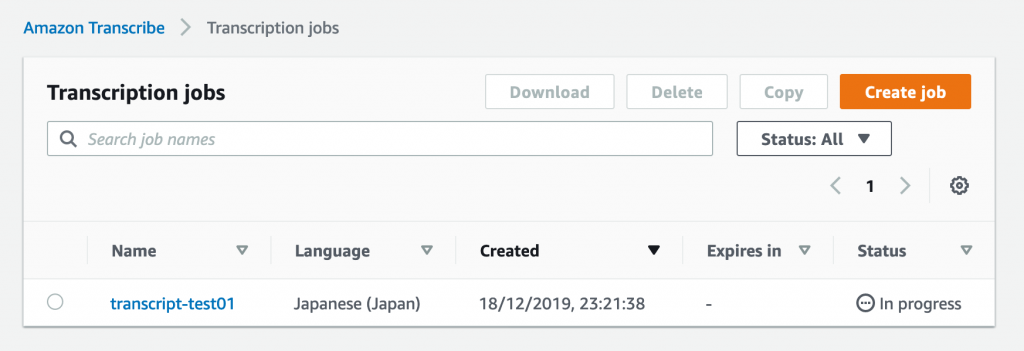
しばらく(今回の音声では数分)待ってステータスが「Complete」になれば、Nameをクリックして詳細画面を開けるようになります。ここで「Download full transcript」ボタンを押すと、JSON形式の変換結果(asrOutput.json)をダウンロードできます。
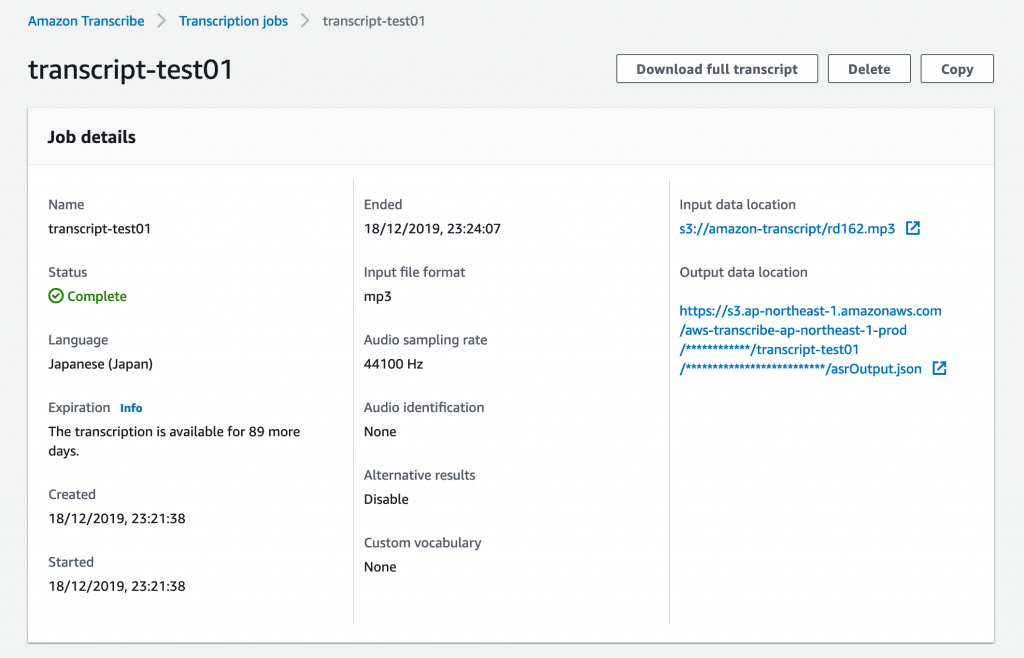
なお、変換結果のテキストは画面の下半分でもプレビュー表示されます。ここでは各単語をマウスオーバーすると、音声中の登場時刻と確度が確認できます。
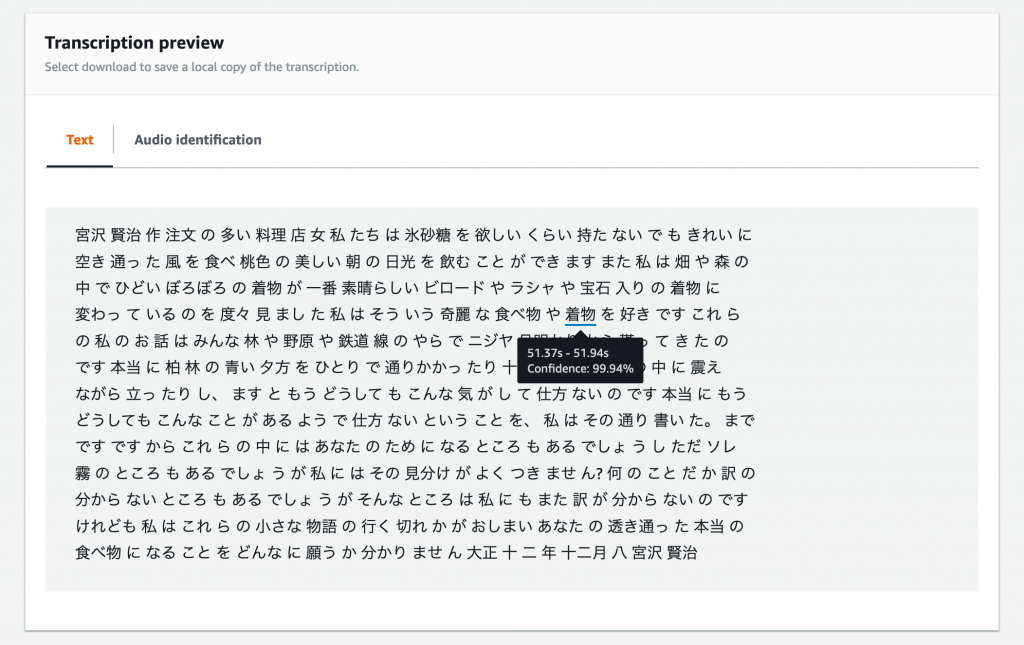
この朗読の原稿となった作品はこちらですが、元の文章と比べてみても、なかなかに十分実用に足る精度で変換できたと思います。一部に誤字や誤変換がありますが、読解には問題ないレベルです。ノイズが少なく録音状態が良い、話し方が明瞭であるといった条件もあり、かなり優秀な結果となりました。
ここで、ダウンロードしたJSONファイル(asrOutput.json)を開いてみましょう。内容は以下の形式となっており、変換結果の全文テキストと、プレビュー表示でも得られた単語ごとの情報が含まれています。
{
"jobName": "transcript-test01",
"accountId": "************",
"results": {
"transcripts": [
{
"transcript": "宮沢 賢治 作 注文 の 多い 料理 店 女 私 たち は 氷砂糖 を 欲しい くらい 持た ない で も きれい に 空き 通っ た 風 を 食べ 桃色 の 美しい 朝 の 日光 を 飲む こと が でき ます また 私 は 畑 や 森 の 中 で ひどい ぼろぼろ の 着物 が 一番 素晴らしい ビロード や ラシャ や 宝石 入り の 着物 に 変わっ て いる の を 度々 見 まし た 私 は そう いう 奇麗 な 食べ物 や 着物 を 好き です これ ら の 私 の お 話 は みんな 林 や 野原 や 鉄道 線 の やら で ニジヤ 月明かり から 貰っ て き た の です 本当 に 柏 林 の 青い 夕方 を ひとり で 通りかかっ たり 十一月 の 山 の 風 の 中 に 震え ながら 立っ たり し、 ます と もう どうして も こんな 気 が し て 仕方 ない の です 本当 に もう どうしても こんな こと が ある よう で 仕方 ない という こと を、 私 は その 通り 書い た。 まで です です から これ ら の 中 に は あなた の ため に なる ところ も ある でしょ う し ただ ソレ 霧 の ところ も ある でしょ う が 私 に は その 見分け が よく つき ませ ん? 何 の こと だ か 訳 の 分から ない ところ も ある でしょ う が そんな ところ は 私 に も また 訳 が 分から ない の です けれども 私 は これ ら の 小さな 物語 の 行く 切れ か が おしまい あなた の 透き通っ た 本当 の 食べ物 に なる こと を どんな に 願う か 分かり ませ ん 大正 十 二 年 十二月 八 宮沢 賢治"
}
],
"items": [
{"start_time":"2.94","end_time":"3.53","alternatives":[{"confidence":"0.9919","content":"宮沢"}],"type":"pronunciation"},
{"start_time":"3.53","end_time":"3.95","alternatives":[{"confidence":"1.0","content":"賢治"}],"type":"pronunciation"},
{"start_time":"3.95","end_time":"4.45","alternatives":[{"confidence":"0.9434","content":"作"}],"type":"pronunciation"},
{"start_time":"5.84","end_time":"6.48","alternatives":[{"confidence":"1.0","content":"注文"}],"type":"pronunciation"},
{"start_time":"6.48","end_time":"6.63","alternatives":[{"confidence":"1.0","content":"の"}],"type":"pronunciation"},
{"start_time":"6.63","end_time":"6.94","alternatives":[{"confidence":"1.0","content":"多い"}],"type":"pronunciation"},
{"start_time":"6.94","end_time":"7.29","alternatives":[{"confidence":"1.0","content":"料理"}],"type":"pronunciation"},
{"start_time":"7.29","end_time":"7.54","alternatives":[{"confidence":"1.0","content":"店"}],"type":"pronunciation"},
{"start_time":"8.64","end_time":"8.92","alternatives":[{"confidence":"0.2984","content":"女"}],"type":"pronunciation"},
{"start_time":"13.84","end_time":"14.26","alternatives":[{"confidence":"0.98","content":"私"}],"type":"pronunciation"},
{"start_time":"14.26","end_time":"14.57","alternatives":[{"confidence":"1.0","content":"たち"}],"type":"pronunciation"},
{"start_time":"14.57","end_time":"14.78","alternatives":[{"confidence":"1.0","content":"は"}],"type":"pronunciation"},
︙
.results.transcripts.transcript プロパティーには、変換後の全文テキストが含まれています。ただし、各単語が半角スペースで区切られてつながっているため、人間にとっては非常に読みにくいです(笑)。そこで、簡易的に句読点を入れる加工をしてみます。
s/\(です\|ます\|ません\) \(と\|から\|し \)/\1\2、/g s/\(です\|ます\) \(よ\? \?ね \)\?/\1\2。\n\n/g s/\(でし\|まし\) \(た\)/\1\2。\n\n/g s/ //g
このsedスクリプトを通すことで、以下のように比較的読みやすくなります。ここに挙げたパターンではまだまだ不十分だと思いますので、適宜追加してみてください。
$ cat asrOutput.json | jq .results.transcripts[0].transcript | gsed -f punctuation.sed "宮沢賢治作注文の多い料理店女私たちは氷砂糖を欲しいくらい持たないでもきれいに空き通った風を食べ桃色の美しい朝の日光を飲むことができます。 また私は畑や森の中でひどいぼろぼろの着物が一番素晴らしいビロードやラシャや宝石入りの着物に変わっているのを度々見ました。 私はそういう奇麗な食べ物や着物を好きです。 これらの私のお話はみんな林や野原や鉄道線のやらでニジヤ月明かりから貰ってきたのです。 本当に柏林の青い夕方をひとりで通りかかったり十一月の山の風の中に震えながら立ったりし、ますと、もうどうしてもこんな気がして仕方ないのです。 本当にもうどうしてもこんなことがあるようで仕方ないということを、私はその通り書いた。までです。 ですから、これらの中にはあなたのためになるところもあるでしょうしただソレ霧のところもあるでしょうが私にはその見分けがよくつきません?何のことだか訳の分からないところもあるでしょうがそんなところは私にもまた訳が分からないのです。 けれども私はこれらの小さな物語の行く切れかがおしまいあなたの透き通った本当の食べ物になることをどんなに願うか分かりません大正十二年十二月八宮沢賢治"
本番の音声データを解析してみる
ここまでで、朗読音声がいい感じに変換できることが分かりましたので、実務に応用できるか検証してみます。実際の会議の様子を音声録音したデータをTranscribeで変換してみました。品質の高いテキストが得られれば議事録作成に役立ちますが、今回は以下のような傾向が見られました。
- (原稿を読むのではなく)内容を考えながら会話をするケースでは、部分部分で話す速度や音量が変化することから、誤認識が多い傾向がある。
- 声のボリュームが小さい箇所は、認識されずテキストから抜け落ちる。一人が発した一文が丸ごと消えてしまうことも。
- 個々の会社名、人名などの固有名詞は、本来とは異なるが音が似たフレーズに誤認識されやすい。
会議机の上に置いたICレコーダーで録音した音声だったため、ノイズが乗っていたり、参加者の距離によって音量が異なったりと、若干厳し目の条件でした。それもあり、結局「本当は何と言っているのか?」を音声を聞いて聞き取りすることになり、「そのまま議事録に載せられる」というところからは程遠い結果となってしまいました。とすると、変換結果の品質を上げるには、「発言ははっきりと明瞭に行う」「一定の速度と声量で話す」ことを会議参加者に心がけていただく必要が出てきそうです。ただし、今回の結果であっても「どの辺りでどのような内容を話していたか」といった会話の流れを把握する目的には使えそうだということが分かりました。
なお、誤認識された単語の中には次のようなものがありました。
本来の単語 → 認識された単語
ハードウェア → 母親
描(えが)かせて → 映画化して
〜を取る方 → 踊る方
〜さん → 〜ちゃん
なんとか頑張って認識しようという健気さが感じられて、微笑ましく思えます(笑)。今後の成長に期待したいですね。
- Tweet
-

 2024/05/10
2024/05/10 2023/08/18
2023/08/18 2022/12/23
2022/12/23 2022/11/18
2022/11/18 2022/10/14
2022/10/14 2022/09/09
2022/09/09 2022/08/19
2022/08/19 2022/07/22
2022/07/22