ギーク
Voice-Based Emotion Classification
senaka
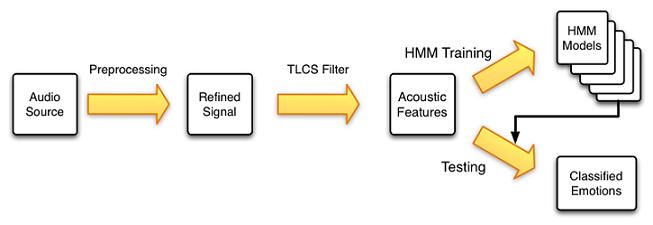
Flow of emotion classification
Recent advances in computer and Internet technology enable increasingly seamless interaction between human and machines. Applications such as Internet games, 3D collaborative virtual environments (eg Second Life), and web-based teaching involve interaction between human and machine.
Emotionless communication between humans is really dull. Enriching such communications with emotions leads to a successful communication in personal environments and business environments. Voice is a reasonable biometric parameter to extract an emotional state of a speaker.
Voice-based emotion classification process can be divided into two major parts. Those are feature extraction and emotion classification. In feature extraction process, features which contain emotional cues of voice are computed. In classification process, features are compared with free defined emotion models.
Mel-Frequency Cepstral Coefficients are popular among research community as a successful feature set. Once features are extracted, this becomes a pattern classification problem and classifiers such as Hidden Markov Models (HMMs) and Artificial Neural Networks (ANNs) can be deployed. The above diagram illustrates emotion classification process uses Two-Layered Cascaded Cepstral Coefficients as features and HMMs as a classifier.
- Tweet
-

 2024/05/17
2024/05/17 2024/01/05
2024/01/05 2023/12/08
2023/12/08 2023/11/17
2023/11/17 2023/07/07
2023/07/07 2023/05/12
2023/05/12 2023/02/24
2023/02/24 2022/12/23
2022/12/23